SCS; modeling
0x30. modeling
Two stage ML
0x31. model 선정과정
1. 단일 모델 기반 접근과 그 한계
분석 초반에는 단일 LightGBM 모델을 사용하여, 공간 블록 기반 교차 검증과 SHAP 분석을 수행하였다. 이 모델은 다음과 같은 기술적 장점을 갖고 있어 초기 실험용으로 적합하다고 판단하였다:
- XGBoost보다 메모리 효율성이 높고 학습 속도가 빠름
- 복잡한 비선형 관계를 효과적으로 모델링할 수 있으며
- 결측치나 범주형 변수 처리에 있어서도 유연성을 갖춤
하지만 실제 실험 결과, 다음과 같은 구조적 한계에 도달하게 된다
-
극심한 클래스 불균형 (양성 비율 약 0.0009)으로 인해 재현율은 높게 유지되었으나, 정밀도가 낮게 나타남
-
'sinkhole_area_pipe_risk'라는 단일 피처에 모델의 예측이 과도하게 의존하는 경향이 있었고
-
결과적으로 일반화 성능과 해석 가능성 모두 제한적이었다 이러한 문제를 해결하고자, 다음과 같은 개선을 시도하였다:
2. 개선 시도
- 1차로는 SMOTE 오버샘플링을 적용하여 클래스 분포를 인위적으로 보정하였지만, 오히려 정밀도가 더 저하되며 과적합 가능성이 높아지는 결과를 낳았다.
- 2차로는 LightGBM과 IsolationForest를 단순 앙상블 방식으로 결합했지만, 성능 개선 폭은 제한적이었다.
3. 문제 구조 재해석 및 설계 방향 수립
이후 본 과제가 갖는 데이터적·도메인적 특성을 분석하며, 문제를 구조적으로 재정의하였다
- 침하 사고는 공간적으로 군집성을 보이는 경향이 있으므로 공간 정보의 활용이 필수적이며 데이터는 극단적으로 희귀한 사건에 대한 예측 문제이므로 전통적인 분류 접근만으로는 성능 한계가 분명했다
- 지역별로 피처의 영향력이 크게 달라지는 특성을 갖고 있었고 수십만 그리드 단위의 예측이 필요하므로 계산 효율성 또한 고려 대상이었다
4. Two-Stage 모델 구조의 채택
이러한 고민 끝에, 문제를 2단계로 분리하여 해결하는 Two-Stage Hybrid Modeling 구조를 설계하였다.
- Stage 1에서는 단순한 근접성 기반 로지스틱 회귀 혹은 LightGBM을 통해 전체 그리드 중 위험 후보군을 빠르게 선별하고
- Stage 2에서는 선택된 후보군에 대해 GNN based 정밀 예측 모델을 적용하여 위험도를 재평가하는 구조로 구성하였다.
- 특히 Stage 2에는 Graph Neural Network (GraphSAGE)를 도입하였는데, 이는 침하 위험이 공간적으로 확산되거나 인접 그리드 간 영향이 존재할 수 있다는 도메인적 가설을 모델링하기 위해서이다.
- 또한 Uncertainty-Masked GraphSAGE 설계를 통해 불확실성이 높은 지역에 계산 자원을 집중하는 효율적 학습 방식도 적용하였다.
0x32. model structure
0. 핵심 아이디어
- Two-stage screening: 초기에는 proximity prior(예: min_distance_to_sinkhole)를 이용해 전체 그리드를 빠르게 평가한 뒤, 두 번째 단계에서 contextual model을 적용
- Uncertainty-aware candidate sampling: Stage 1에서 명백한 음성 샘플을 제외하고, 불확실성(entropy)과 잠재적 위험도를 기준으로 후보 영역을 선별
- UM-GraphSAGE: spatial message passing과 entropy-based masking을 결합해 노드 간 관계를 효과적으로 학습
- Silent-zone PU learning: 관측되지 않은(high-risk) 지역에 대한 positive-unlabeled 학습으로 사각지대 보완
- Hyperparameter Caching: Stage 1 점수를 재활용해 하이퍼파라미터 탐색 속도를 대폭 개선
1. architecture 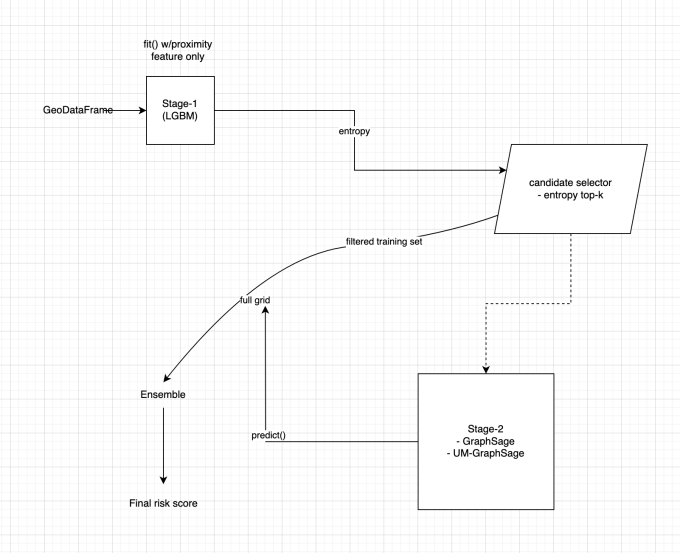
2. 데이터 레이어 (Data Layer)_SinkholeCivicSentinel
-
Load
- PostGIS DB에서 GeoDataFrame으로 스트리밍 로드(load_dataset)
- WKB hex를 shapely로 디코딩해 geometry 복원
-
Spatial Blocks
- KMeans를 이용한 공간 교차검증 블록 생성(create_spatial_blocks)
- GroupKFold를 위해 동일 블록 인덱스 유지
-
Silent Zones
- Stage 1 확률이 낮거나 관측되지 않은(non-subsidence) 영역 중 상위 percentile(get_silent_grid_ids)을 silent-zone으로 지정
- 거리가 없을 경우 무작위로 5% 선택
3. 1단계: Proximity Model (Stage 1)
- Model: LightGBM 또는 LogisticRegression
- Input: 단일 feature
- Train/Val Split:
- 공간 블록 있을 시 GroupKFold
- 없을 시 StratifiedShuffleSplit
- 불균형 처리: scale_pos_weight = #negative / #positive
- Output: 각 그리드의 확률 p₁
- Threshold Tuning: IoU@100 기준 threshold_percentile 자동 최적화
4. 후보 선택 : uncertainty sampling
- 목적: 명백한 negative를 제거하고, 확률 분포 상 불확실하거나 잠재적 위험 지역 집중
- 기준: 확률 하위 percentile + entropy 상위 k개
def select_candidates_with_uncertainty(model, X, percentile=80, uncertainty_topk=1000):
probs = model.predict_proba(X**[(draft yet): 'min_distance_to_sinkhole']**)[:,1]
entropy = -(probs*np.log(probs+1e-6)+(1-probs)*np.log(1-probs+1e-6))
low_prob_idx = np.where(probs < np.percentile(probs, percentile))[0]
top_uncert_idx = np.argsort(entropy)[-uncertainty_topk:]
candidates = np.unique(np.concatenate([low_prob_idx, top_uncert_idx]))
return candidates
5. 2단계: GraphSAGE & UM-GraphSAGE (Stage 2)
EnhancedGraphSAGE
- Input: in_channels, optional feature_weights
- Structure:
- Feature weighting layer (선택적)
- 2-layer GraphSAGE with ReLU, dropout
- Jumping Knowledge(jk='cat')
- 최종 Linear + Sigmoid
EnhancedUncertaintyMaskedGraphSAGE
- Base: UncertaintyMaskedGraphSAGE
- Masking: uncertainty_low, uncertainty_high 경계로 노드 필터링
- Backbone: EnhancedGraphSAGE
6. Training Wrapper: EnhancedTwoStageSinkholeScreener
-
fit
- Stage 1 학습
- candidate mask 생성
- Stage 2 학습 (GraphSAGE)
- Validation metrics(AUC/PR-AUC) 계산 및 로깅
-
predict
- GNN 경로: geometry → radius_graph → forward
- Unsupervised 경로: Stage 1 확률 직접 반환
7. 최종 위험 점수 (Final Risk Score)
- Stage 1 확률(p₁)과 Stage 2 출력(p₂)을 조합하거나
- GNN 모델만으로 최종 risk_score 산출
- 시각화 및 정책 반영을 위한 risk_score 맵 생성